課題と解決方法
テンプレート作成時の項目の囲い方によって、不自然に先頭文字が欠けることがあります。
以下、例を交えて対応方法をご紹介します。
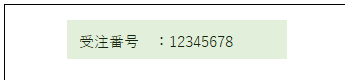
下記のような帳票から、受注番号を読み取りたいとします。

確実な方法は、テンプレート作成時、以下のように読み取りたい領域(緑色の部分)を設定した後、除外文字に「受注番号:」を指定することです。
もし様式の変更が可能なら、以下のように読み取りたい項目を枠で囲むことを強くお勧めします。

ところで、以下のように、読み取りたい領域を設定することも考えられます。
こちらの方が一般的ですね。
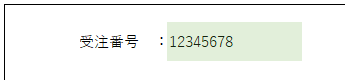
この設定時、まれに認識結果の先頭の文字が欠けることがあります。
このような文字欠けが発生する時は、一旦大きく囲ってから、不要な文字を除外文字の設定で削除することで対処できることが多いです。

除外文字機能については、 [領域詳細設定]-[変換設定①]について を参照願います。
理由
以降、技術的な内容ですので、興味のある方だけ。
何故こんなことが起きるのでしょうか。
AI JIMY では、ページを丸ごと文字認識して、必要な箇所だけを切り取る作りになっています。
その時、一文字一文字ではなく、文字のブロック(かたまり)で文字を認識します。
下記の例では、「受注番号 :12345678」のブロックにまとめて認識しました。
これは文字認識エンジンの仕様で、どこで分けるか、分けないかはケースバイケースになります。

読み取りたい領域は、下記の緑色の部分です。

緑色の範囲内に含まれる認識結果のブロックは、「受注番号 :12345678」です。
このままでは、認識結果も「受注番号 :12345678」になってしまい、読み取りたい領域と異なります。
そこで、赤枠の左端と緑部分の左端の位置の差を元に、前から何文字削除するかを計算し、文字を削除します。
この場合、6文字分削除すると、認識結果は「12345678」で期待通りなのですが、
位置ずれなどの理由で7文字分と判断されると、前から7文字削除して認識結果は「2345678」になってしまいます。
別の例を挙げます。
下記の例では、「受注番号」と「:12345678」の二つのブロックに分けて認識しました。
これも文字認識エンジンの仕様で、どこで分けるか、分けないかはケースバイケースになります。

読み取りたい領域は、下記の緑色の部分です。

緑色の範囲内に含まれる認識結果のブロックは、「:12345678」です。
このままでは、認識結果も「:12345678」になってしまいます。
そこで、右側の赤枠の左端と緑部分の左端の位置の差を元に、前から何文字削除するかを計算し、文字を削除します。
この場合、1文字分削除すると、認識結果は「12345678」で期待通りなのですが、
位置ずれなどの理由で2文字分と判断されると、前から2文字削除して認識結果は「2345678」になってしまいます。
明確に空白を含むと、文字認識エンジンはブロックを分けて認識することが多いです。
例えば、

や

のようなレイアウトだと、項目名と番号自体が離れるため、文字認識エンジン自体が期待される位置でブロックを分割し、「12345678」を取得できる可能性が高いです。
「読み取り位置の微調整」または、「まとめて読み込んで除外文字を指定して不要な文字を削除」することで対応していただくことも出来ますが、もし可能であれば、AI OCRが読み取りやすい帳票様式へ変更していただく事で認識精度が向上しますので、お試しください。
これ以外にも、AI OCR が得意な帳票、不得手な帳票もあります。少しデザインを変更するだけで読み取り精度が上がることもありますので、お気軽にお尋ねください。
